Beim Datenmanagement haben deutsche Unternehmen Nachholbedarf, wie eine Studie von Experian zeigt. 23 Prozent der Befragten glauben, dass sie durch mangelnde Datenpflege finanzielle Einbußen erleiden.
Lediglich 27 Prozent der deutschen Unternehmen bezeichnen den Umgang mit ihren Daten und deren Verwaltung und Pflege als hoch entwickelt. 86 Prozent befürchten, dass die Informationen im eigenen Haus ungenau und für datenbasiertes Marketing unbrauchbar sind. Zu diesen Ergebnissen kommt die jährliche weltweite Studie ‚Datenqualität als kritischer Erfolgsfaktor‘, des Cross Channel Marketing-Spezialisten Experian Marketing Services.
Die Menge an fehlerhaften oder ungenauen Datensätzen steigt laut Studie seit Jahren an: Waren im Jahr 2013 durchschnittlich 17 Prozent der Daten fehlerhaft, so lag der Anteil der fehlerhaften Datensätze im Folgejahr bereits bei 22 Prozent und 2015 bei durchschnittlich 26 Prozent. Global glaubte 2015 knapp ein Viertel der Befragten (23 Prozent), dass sie durch Nichtbereinigung von Datenfehlern Geld verliert. Das entspricht einem Zuwachs von 19 Prozent im Vergleich zum Vorjahr. Fast jedes zweite Unternehmen (46 Prozent) entdeckt nach eigenen Angaben die Datenmängel erst, wenn Mitarbeiter oder Kunden drauf stoßen.
Steigende Datenmenge erschwert das Management
„Den strategischen Wert von qualitativ hochwertigen Daten zur Steigerung der Wertschöpfung haben die Unternehmen haben längst klar erkannt“, erläutert Gregor Wolf, Geschäftsführer Experian Marketing Services Deutschland. „Die Menge der Daten nimmt allerdings stärker zu als die Fähigkeit der Unternehmen, die Informationen zu strukturieren und zu beherrschen.“ Um die Datenqualität zu steigern, empfiehlt Experian eine klar definierte Datenstrategie, ein zentralisiertes Datenmanagement sowie automatisierte Systemen, die helfen, Fehlerquellen dauerhaft zu reduzieren. Nun nutzen zwar 94 Prozent aller deutschen Unternehmen technische Lösungen zur Bereinigung der Daten, allerdings liegen die Daten selbst in den meisten Fällen in voneinander abgeschotteten Silos. Lediglich 31 Prozent der Unternehmen nutzen Technologien zur Abstimmung und Verbindung von Daten, 32 Prozent zur Datenprofilierung und 34 Prozent setzen Technologien zur Überwachung und Prüfung ein.
Die folgende Übersicht stellt sieben Lösungen vor, mit denen Unternehmen die Qualität ihrer Daten fortlaufend messen und darüber hinaus Pflegeaktionen starten können.
InfoZoom prüft Daten bei der Auswertung
InfoZoom vom Hersteller HumanIT ist eine am Fraunhofer Institut entwickelte Lösung zur Datenauswertung. Die Technologie ermögliche die unmittelbare Prüfung kompletter Datenbestände vor und während der Auswertung Nach dem sekundenschnellem Datenimport visualisiere InfoZoom alle relevanten Feldinhalte sortiert, werteverteilt und interaktiv auf einer Bildschirmbreite. Auch bei Millionen von Datensätzen entstehe so ein komplettes Bild der Datenbasis. Auf einen Blick seien unter anderem Füllungsgrade, fehlerhafte Einträge oder Dubletten zu erkennen. Auch Auffälligkeiten, die bisher nicht bekannt waren oder nach denen gar nicht gesucht wurde, fielen ins Auge. So spüre InfoZoom auch logische Inkonsistenzen oder interessante Datenkonstellationen auf, die in anderen regelbasierten Systemen nicht erkennbar seien.
Die anschauliche Darstellung kompletter Datenmengen bringe Vorteile für IT-Projekte: Alle Beteiligten erhielten ein transparentes, realistisches und einheitliches Bild der Datenlage. So hätten in Projekten zur Datenqualität alle Stakeholder, vom Fachanwender über IT-Experten bis zum externen Dienstleister, das gleiche Verständnis für die Daten.
Bereits nach kurzer Einführung könnten Fachanwender beliebig großen Datenmengen analysieren, schneller und flexibler als mit SQL-Abfragen oder MS Excel. Auch Kennzahlen und Reports ließen sich schnell erstellen. InfoZoom mache Fachabteilungen unabhängig im Qualitätsmanagement und bei der Analyse ihrer Daten. Die Lösung werde ergänzend zu vielen BI- (Business Intelligence), ERP-(Enterprise Resource Planning) und CRM-Systemen (Customer Relationship Management) oder als Teil von Datenkontrollsystemen eingesetzt. Für die meisten Kunden sei die Analyse der Daten mit InfoZoom der erste Schritt im Datenqualitätsmanagement. Erst nach der Prüfung mit InfoZoom würden Daten in anderen Systemen weiterverarbeitet.
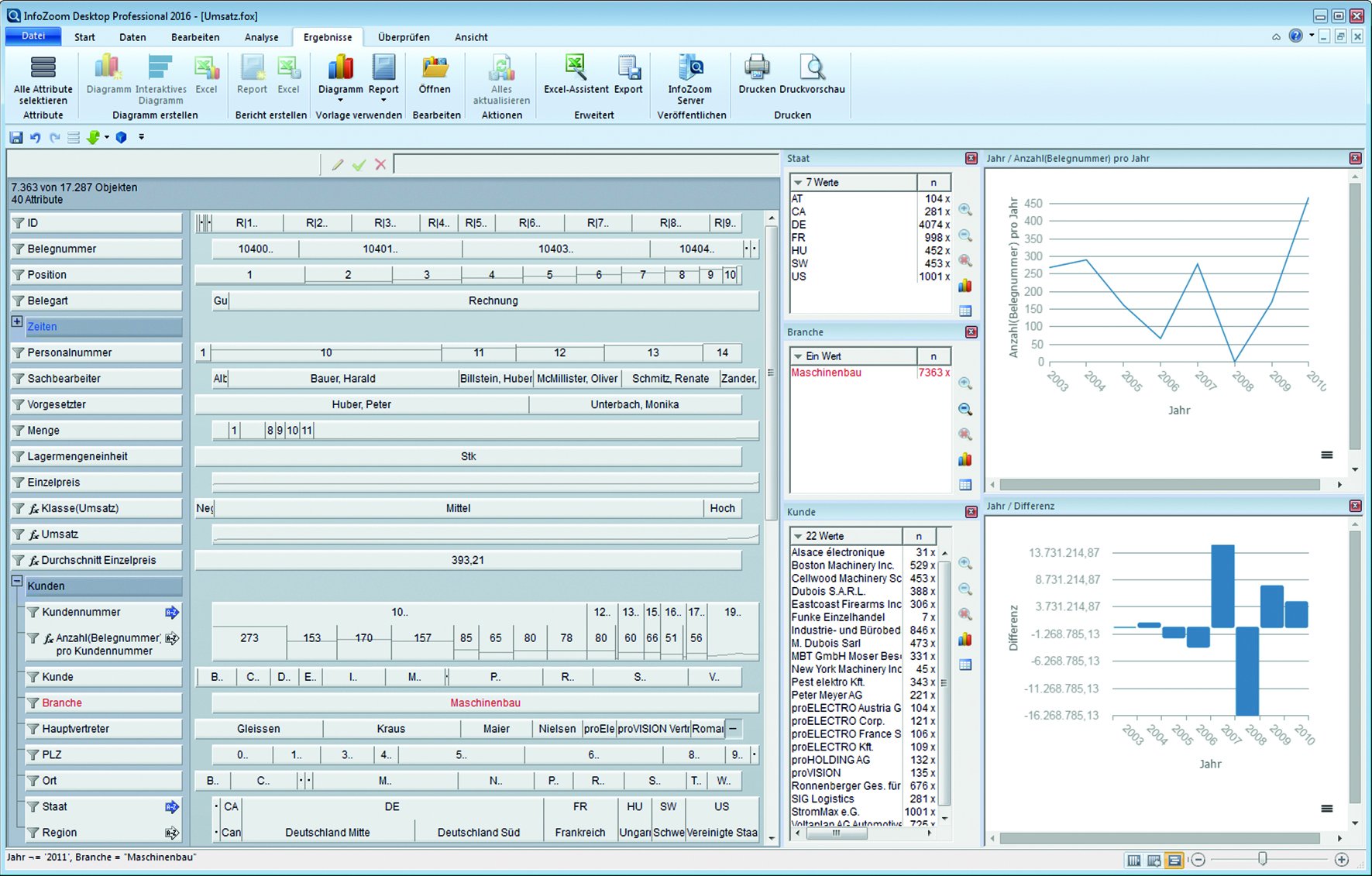
InfoZoom von HumanIT visualisiert sämtliche auszuwertenden Feldinhalte sortiert, werteverteilt und interaktiv auf einer Bildschirmbreite. Quelle: Human IT
Für das regelbasierte Datenmonitoring und Reporting dient das Produkt InfoZoom Data Quality Control. Unternehmen erstellten damit ihr individuelles Regelwerk zur automatisierten Fehlerauswertung. Auf Basis von r Reports könnten Sachbearbeiter die ermittelten Fehler gezielt beheben. Ein automatisiertes Monitoring zeige die Datenpflegemaßnahmen.
Informatica optimiert die Qualität über Prozesse
Zuverlässige und bereinigte Daten betrachtet Informatica als wichtige Voraussetzung für den wirtschaftlichen Erfolg von Unternehmen. Wiederholbare Prozesse könnten die Sicherstellung der Datenqualität unterstützen. Zu diesen Prozessen gehöre beispielsweise die Festlegung der besonderen Anforderungen an ‚gute‘ Daten für jeden Ort, an dem sie genutzt werden, die Festlegung von Regeln zur Bestätigung der Qualität der jeweiligen Daten, die Integration dieser Regeln in einen bestehenden Workflow, jeweils mit der Möglichkeit, Ausnahmen zu testen und zu behandeln sowie die kontinuierliche Überwachung und Erfassung der Datenqualität während ihres Lebenszyklus. Erfolgreiche Datenqualitätsinitiativen müssten darüber hinaus gut skalieren, damit sie sich geänderten Regeln und Bedarfslagen gegebenenfalls anpassen könnten.
Lösungen von Informatica schlagen beim Import von Daten automatisch Lösungen zu deren Bereinigung, Optimierung und Anreicherung vor. Quelle: Informatica
Produktseitig biete die Lösung Informatica Data as a Service verschiedene Dienste zur Datenqualität und Datenanreicherung sowie mobile Dienste mit fehlerfreien, überprüften Daten. So lasse sich eine zuverlässige und stets korrekte Kontaktaufnahme mit den Kunden sicherstellen. Die Lösung Informatica Data Quality umfasse mehrere Werkzeuge, die unabhängig von Datenvolumen, -format oder der verwendeten Plattform zum Einsatz kämen. Anwender könnten unabhängig von der IT-Abteilung Geschäftsregeln definieren und testen. Darüber hinaus erlaube die Lösung das Hinzufügen von Ausnahmen, die Identifizierung von Beziehungen zwischen einzelnen Datenobjekten sowie die Deduplizierung und Zusammenführung von Daten. Mit der virtuellen Datenmaschine Informatica Vibe und der Technologie Map Once, Deploy Anywhere sei es Unternehmen zudem möglich, Regeln für die Datenqualität einmal zu erstellen und diese dann direkt auf der Informatica Platform, in Hadoop, in der Cloud oder eingebettet in den Unternehmens-Anwendungen auszuführen.
Im Sinne der Datenqualität müssten Daten vor einer Analyse stets aufbereitet werden. Um diesen Prozess zu vereinfachen, schlagen die Lösungen von Informatica automatisch Optionen zur Bereinigung, Optimierung und Anreicherung vor, sobald Daten importiert würden. Das gelte unabhängig davon, ob die Daten von einem Inhouse-System, aus der Cloud oder aus einer anderen Quelle stammten.
Omikron setzt auf die serviceorientierte Architektur
Die Omikron-Lösungen zur Pflege der Datenqualität sind laut Herstelleraussage darauf ausgerichtet, die Datenbestände mit schlanken Verfahren in kurzer Zeit zu bereinigen, neu zu strukturieren und vor neuerlichen Daten-Chaos zu schützen. Eine Schlüsselrolle spiele dabei das Konzept der serviceorientierten Architektur (SOA). Damit ließen sich Schritt für Schritt alle kritischen Prozesse absichern. Die Workflow-Engine vereinfache das Erstellen solcher Prozesse von der IT-Abteilung. Der Omikron Data Quality Server sei von Grund auf für SOA entwickelt und lasse sich deshalb von jeder Stelle der Unternehmens-IT aus nutzen. Dies sei vor allem dann wichtig, wenn heterogene Systemlandschaften mit unterschiedlichen Datensilos eine systemübergreifende Sicht auf die Stammdaten verhinderten. Auch sehr schnelle In-Memory-Abgleiche für große Datenbestände von mehreren Millionen Adressen seien mit der Technologie von Omikron möglich.
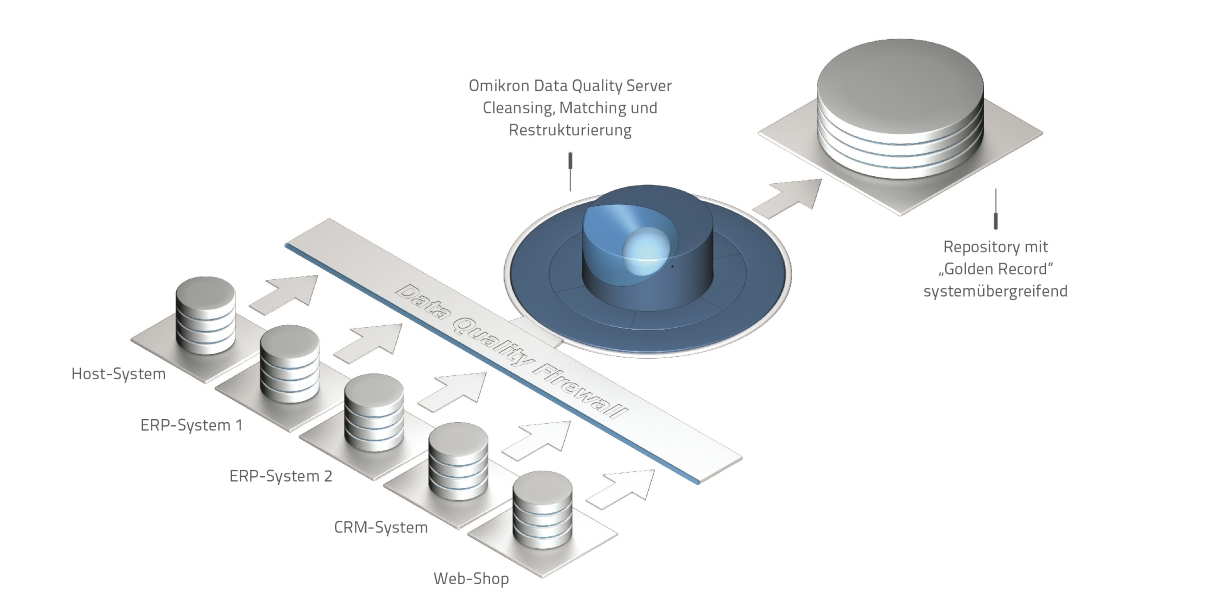
Der Omikron Data Quality Server sorgt dafür, dass sämtliche Daten geprüft und bereinigt werden, bevor sie in die IT-Systeme gelangen. Quelle: Omikron
Omikron-Technologie sorge beim Eingang neuer Daten, beispielsweise bei der Online-Registrierung von Kunden im Webshop und im Call-Center, dafür, dass die Daten geprüft und nach individuellen Erfordernissen bereinigt würden, bevor sie in das System gelangten. Eine Matching Engine erkenne Ähnlichkeiten und Dubletten nach menschlichen Ermessen – sogar bei internationalen Daten. Bei Bedarf könnten die Daten in einem zentralen Repository zusammengeführt werden – mit Verweis auf die Originalquelle. Die Struktur der Quellsysteme werde dabei nicht angetastet.
Der Data-Quality-Circle für eine nachhaltige Datenqualität umfasst nach Auffassung von Omikron die folgenden Punkte: die Messung – also das Bestimmen der Fehlerarten und der Fehlerquote, die Datenanalyse – also die Untersuchung der Fehlerquellen und Bestimmung der Ursachen für unsaubere Daten, die Restrukturierung – also die Normalisierung und Restrukturierung der Daten und Datenformate, die Korrektur – also die Überprüfung und Anpassung der Daten auf Basis von Referenz-Verzeichnissen, die Dublettenprüfung – das Identifizieren im System mehrfach enthaltener Datensätze, die Anreicherung – das Ergänzen der Daten mit Zusatzinformationen, die Konsolidierung – das Zusammenführen verschiedener Datenquellen und schließlich den Report – die kontinuierliche Überwachung des Datenqualitäts-Prozesses.
Sinequa nutzt die Methoden der Linguistik
Die Lösung Sinequa des gleichnamigen Anbieters für Big Data Inhaltsanalyse kombiniert laut Herstelleraussage semantische und statistische Analyse, stellt Zusammenhänge in heterogenen, großen Datenmengen her und liefert Anwendern dadurch Ergebnisse für ihre Arbeitsprozesse. Die Anwendung basiere auf einer patentierten semantischen sowie linguistischen Analyse des Natural Language Processing in 19 Sprachen und lasse sich zur Analyse strukturierter und unstrukturierter Daten einsetzen.
Mit rund 90 Prozent liege heute ein Großteil geschäftlicher Informationen in unstrukturierter Form vor (E-Mail, PDF, Archivsysteme). Sinequa führe strukturierte und unstrukturierte Daten zusammen und sei in der Lage, beide Datenwelten in sehr großer Menge zu indexieren. So erhalte der Anwender auch Fundstellen angezeigt, in denen der eigentliche Begriff gar nicht vorkomme, sondern Synonyme oder inhaltlich ähnliche Begriffe. Durch die kombinierte Analyse entstehe ein semantisch angereicherter Search Index. Auf Basis dieses Rich Index ließen sich so genannte ’Search Based Applications’ erstellen – Anwendungen zur dedizierten Informationsbeschaffung für einzelne Nutzergruppen.
Die Analyselösung Sinequa umfasst rund 150 Konnektoren zu Repositorien für strukturierte und unstrukturierte Daten aus Anwendungen, Cloud und Big Data Hadoop-Umgebungen. Quelle: Sinequa
Über die Sinequa-Plattform bekämen Anwender einen einheitlichen Informationszugang (Unified Information Access) auf das gesamte Unternehmenswissen. Mit der Technologie Smart-Connector stelle die Software Anschlüsse bereit, mit denen Unternehmen neue Datenquellen ohne aufwändige Eigenprogrammierung an die Big-Data-Analyse anschließen könnten. Der Produktumfang umfasse derzeit rund 150 Konnektoren zu den meistverbreiteten Repositorien für strukturierte und unstrukturierte Daten aus Anwendungen, Cloud und Big Data Hadoop-Umgebungen.
Nutzer der Such- und Analyse-Plattform könnten wahlweise on-Premise oder über die Amazon-Cloud auf Informationen zugreifen. Die Software werde idealerweise dort installiert, wo die Daten liegen. Unternehmen könnten so bei der Ausdehnung auf neue Datenquellen zeitnah die benötigte Infrastruktur bereitstellen und damit schneller sowie kostengünstiger Wissen aus verstreuten strukturierten und unstrukturierten Daten generieren.
TIQ Solutions visualisiert Big Data
Die Big Data-Datenqualitätsplattform der Firma TIQ Solutions entdeckt laut Aussage des Anbieters Qualitätsprobleme in großen oder komplexen Datenmengen und identifiziert dabei Optimierungspotentiale.
Unternehmen erzeugten täglich eine große und heterogene Menge an Datensätzen: Kunden-, Mess- und Metadaten sowie Logfiles, Inhalte aus sozialen Netzwerken, Dokumente oder Grafiken. Eine klassische Datenqualitätsanalyse stoße hierbei an ihre Grenzen. Die Big Data-Datenqualitätsplattform sei auf die Verbesserung der Datenqualität großer Datenmengen zugeschnitten und identifiziere Zusammenhängen, Ereignisse und Auffälligkeiten in den Daten. Um Lizenzgebühren zu reduzieren nutze TiQ Solutions Open-Source-Technologien.
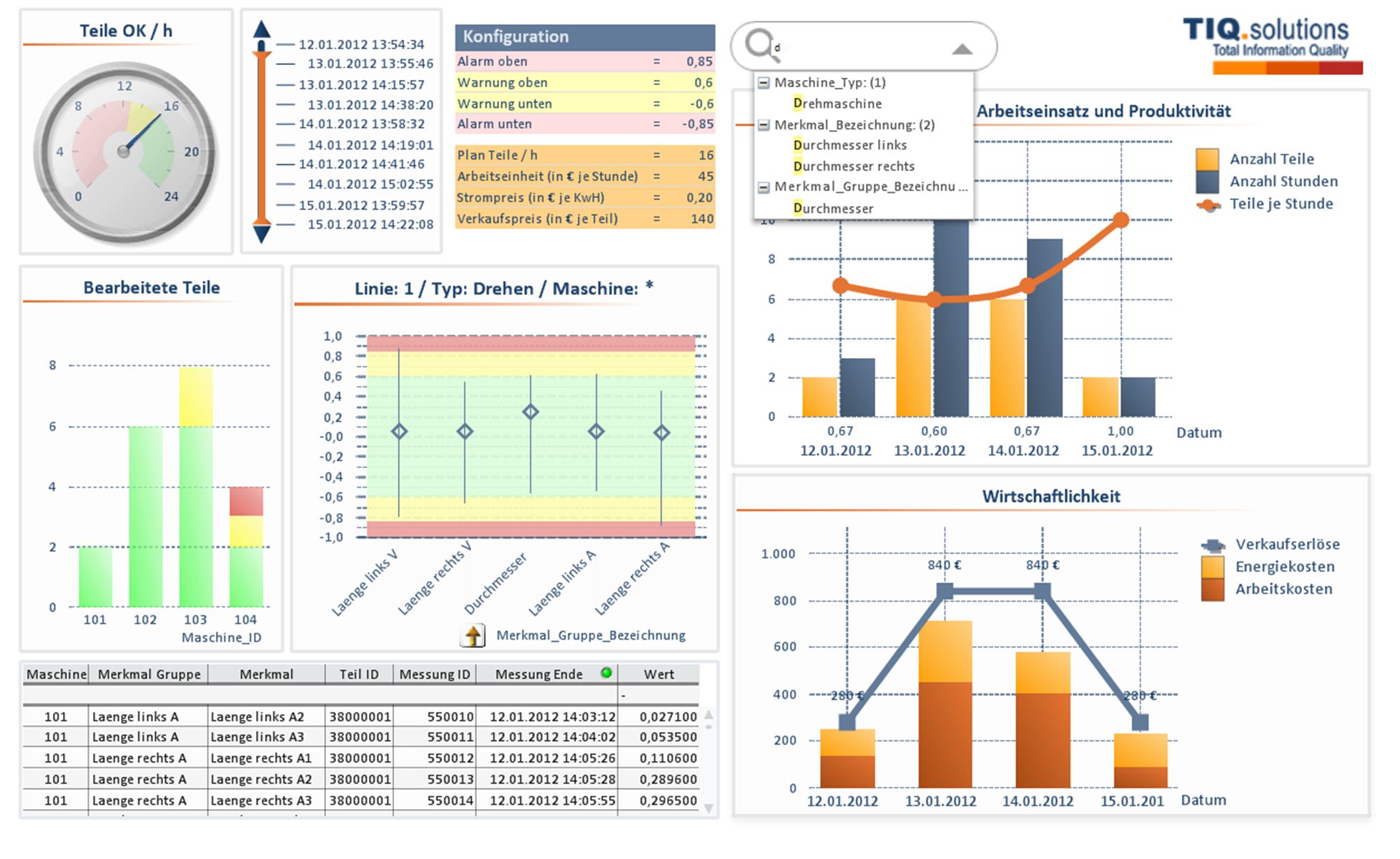
Die Big Data-Datenqualitätsplattform von TIQ Solutions visualisiert die Ergebnisse der Big-Data-Analyse. Quelle: TIQ Solutions
Zur Steigerung der Datenqualität werde ein Big Data-Analyse-System zur strukturierten Erfassung und Modellierung von Störungen aufgebaut. Mithilfe von statistischen Verfahren, Clustering und Assoziationsanalyse werde der Ist-Zustand der relevanten Systeme analysiert, mit dem gewünschten Zustand abgeglichen und potenzielle Anomalien aufgezeigt. Die branchenunabhängige Lösung werde individuell auf die Anforderungen der Kunden zugeschnitten und in einem gemeinsam definierten Prozess implementiert. Standardisierte Komponenten reduzierten die Entwicklungszeit. Nach der Qualitätsprüfung der Quelldaten erarbeiteten die Consulter ein Konzept zu deren systematischer Analyse. Die anschließende Exploration und Modellierung lege den Grundstein für die Datenaufbereitung. Den Abschluss bilde die fachspezifische und Management-orientierte Visualisierung. Damit ließen sich die Ergebnisse auch für Nichtexperten verständlich präsentieren.
Die Big Data-Datenqualitätsplattform von TIQ Solutions ermögliche die Untersuchung und Aufbereitung großer Datenmengen. Die Analyse schaffe eine valide Basis für Reports und Kennzahlen. Konkrete Anwendungsfälle würden gemeinsam mit dem Kunden explorativ entwickelt und modelliert. Ziel sei eine weitgehende Automatisierung der Analyse. Die Plattform lasse sich für das Entdecken von Trends und für Vorhersagen nutzen.
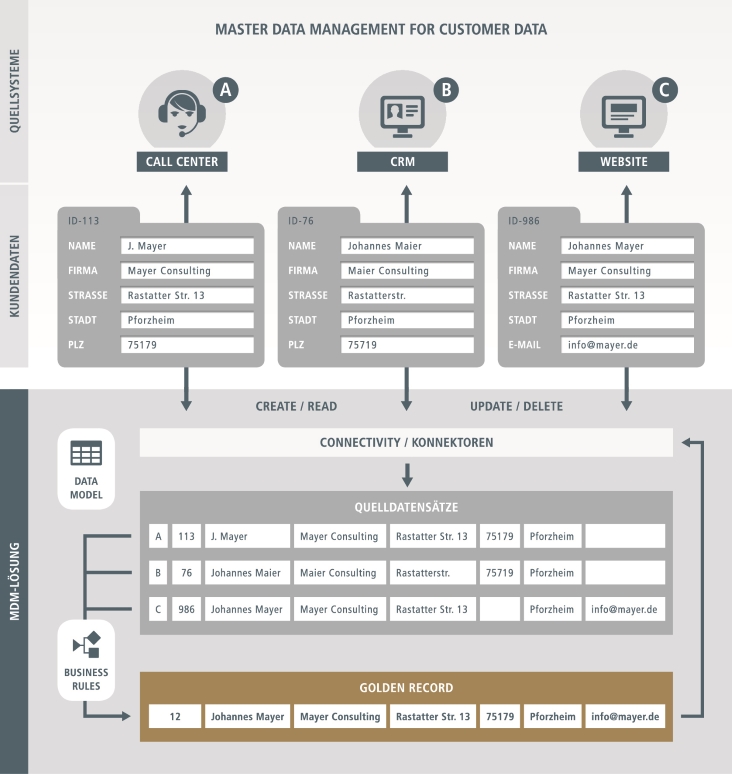
Über den Golden Record versammelt Uniserv sämtliche Kontaktinformationen und gleicht das System für Kundenbeziehungsmanagement (CRM) mit den Callcenter-Informationen und über die Webseite empfangenen Service-Requests ab. Quelle: Uniserv
Uniserv verwaltet Golden Records zentral
Wollen Unternehmen sämtliche Informationen über einen Kunden einsehen, so müssen sielaut Uniserv oft die in verschiedenen Formaten abgelegten Daten in allen Systemen zeitaufwändig einzeln suchen oder diese Systeme teuer integrieren. Datensilos verhinderten eine 360-Grad-Sicht, und Inkonsistenzen in den Daten verwässerten das Kundenbild. Nötig seien daher einwandfreie Kundendatenbestände, der sogenannte Ground Truth, der ein verlässliches Gesamtbild aller Daten gibt. Der Ground Truth setzt sich aus allen kundenbezogenen Daten zusammen – den verfügbaren Kundenstammdaten in Kombination mit kundenbezogenen Interaktions- und Transaktionsdaten.
Mit der Lösung Smart Customer MDM von Uniserv erhalten Unternehmen laut Anbieter eine 360-Grad-Sicht auf ihre Kunden. Der in der Lösung enthaltene Customer Data Hub extrahiere und konsolidiere Kundenstammdaten aus einer Vielzahl heterogener Datenquellen. Bevor die Informationen aus den unterschiedlichen Quellen in den Customer Data Hub integriert würden, sorgten die Datenqualitätstools von Uniserv für bereinigte, strukturierte und aktuelle Daten. So würden bereits bei der Datenerfassung die Datenqualitätsmechanismen greifen. Die Konsistenz der Kundendaten sei über alle Datenquellen hinweg sichergestellt. Auch externe Daten, beispielsweise aus Unternehmenszukäufen oder von Datenlieferanten, ließen sich einfach, sauber und schnell importieren. Dank Uniserv Identity Resolution würden Redundanzen in der Datenhaltung vermieden und die Identitäten von Kunden eindeutig über Prozesse und Systeme hinweg bestimmt.
Die qualitativ optimierten Daten würden zu einem Golden Record oder Single Point of Truth zusammengefasst. Über individuelle Regelwerke lasse sich dieser führende Datensatz automatisiert bearbeiten und ergänzen. Auch eine Synchronisation des Golden Record mit den Quellsystemen sei möglich.
Die Einführung von Smart Customer MDM erfordert laut Uniserv kein komplexes Integrationsprojekt und keine Veränderungen der vorhandenen Datenmodelle. Dank der schnellen Implementierung und der hohe Skalierbarkeit lasse sich mit der Lösung oft bereits nach drei Monaten ein Return on Investment erzielen.
Zetvisions optimiert die Qualität über Domänen
zetVisions SPoT ist eine Multi-Domain-Lösung für das Stammdatenmanagement. Sie sorge für das Zusammenfügensämtlicher im Unternehmen befindlichen statischen Grunddaten oder Referenzdaten zu betriebsrelevanten Objekten wie beispielsweise Produkten, Lieferanten, Kunden und Mitarbeitern zu einem schlüssigen Ganzen, dem Golden Record. Das Ergebnis sei ein Single Point of Truth für alle Arten von Stammdaten, aus dem alle angeschlossenen Systeme bedient würden.

Die Ergebnisse der Datenvalidierung stellt zetVisions SPoT in einem Dashboard dar. Hinterlegt sind dort die Validierungsregeln sowie die Aufgaben. Quelle: Zetvisions
zetVisions SPoT verbessere nicht nur die Qualität und Aktualität der Stammdaten, sondern sorge auch für effizientere Prozesse und Kosteneinsparungen. Gleichzeitig implementierten Unternehmen mit dieser Lösung einen kontrollierten Ablauf für die Pflege ihrer Stammdaten. Die Software unterstütze unternehmensinterne Richtlinien für den Umgang mit Daten. Diese Data Governance definiere Prozesse und Verantwortlichkeiten für Dateneingabe, -freigabe und -pflege. Die Daten könnten dezentral im System erfasst, zentral validiert und an die nachgelagerten Systeme distribuiert werden. Dies geschehe auf Basis von Prozessen, die sich inklusive Freigaben und Workflows von den Unternehmen selbst bestimmen ließen. Belege dokumentierten innerhalb eines Prozesses (Requests), welcher Nutzer beziehungsweise welche Nutzergruppe welche Daten eingegeben, und wer diese Daten auf Basis welcher Informationen freigeben hat. Validierungen könnten Benutzern direkt über die Weboberfläche definieren. Da durch den Einsatz von zetVisions SPoT die Datenpflege nur einmalig anfalle, ließen sich zeitaufwendige und redundante Pflegeaktionen vermeiden.
Mit dem Rundumblick auf die Stammdaten über alle Domänen und den gesamten Geschäftsprozess hinweg leiste zetVisions SPoT einen wichtigen Beitrag zu wirkungsvoller Big Data Analytics. Mit Hilfe der Software sei es möglich, unternehmensweite Zusammenhänge und Wechselwirkungen zwischen den Geschäftsbereichen sichtbar zu machen und so Strukturen in Big Data zu erkennen. Die Lösung liefere damit die Grundlage, um aus ‚guten‘ Daten ‚gute‘ Informationen und sodann mit Hilfe wirkungsvoller Analytik zuverlässiges Wissen zu generieren, das abgesicherte unternehmerische Entscheidungen ermöglicht. jf
Anzeige

Business Intelligence neuester Stand: Die Marktübersicht der BI-Lösungsanbieter und Dienstleister 2015 von isi Medien ist verfügbar. Zum E-Paper hier klicken.
Über Beteiligungsmöglichkeiten für 2016 informieren Sie Frau Fellermeier unter 089/ 90 48 62 23, cfellermeier@isreport.de und Herr Raupach unter 089/ 90 48 62 30.





