Unternehmensverantwortliche erkennen zunehmend den Wert ihrer wachsenden Datenmengen und suchen nach Möglichkeiten diese sinnvoll und kosteneffektiv auszuwerten. Big-Data-Datanalyse im Betriebsmodell Cloud Computing kann eine davon sein. Anbieter setzten dabei auf Schlüsseltechnologien wie Hadoop, bieten allerdings sehr individuelle Big-Data-Lösungen und Frameworks an.
Von Norman Bernhardt und Viktor Adler*
Anbieter wollen mit ihren Produkten den neuen Bedarf für die Analyse von großen und sehr großen Datenmengen, Big Data, decken. Die Datenmassen erreichen hier mitunter Exabyte. Je nach Branche, Fachbereich und Anwendungsfall unterscheiden sich die Ziele und Interessen eines Unternehmens in Bezug auf Big Data stark voneinander. So ist für die Marketingabteilung etwa die Auswertung von Internetzugriffen in Echtzeit ein vordringliches Ziel, während eine Produktionsabteilung Sensordaten sinnvoll auswerten will.
Cloud Computing als Enabler für Big-Data-Analysen
Das Betriebsmodell Cloud Computing kann für Big-Data-Analysen eine Rolle als Enabler spielen. So wird die Auswertung von großen Datenmengen in zahlreichen Punkten unterstützt. Auch kleinere Unternehmen können ohne größeren finanziellen Aufwand auf dieses IT as a Service-Angebot zurückgreifen. Aufgrund der klar definierten Servicemodelle ist es Unternehmen möglich, ohne Entwicklungsumgebung (PaaS) eigene Big-Data-Produkte aufzubauen. Große Datenmengen können ohne eine eigene Serverfarm (IaaS) gespeichert und verarbeitet werden. Schließlich lassen sich Daten mittels bereits bestehender und über die Cloud bereitgestellter Standardsoftware auf virtualisierten Umgebungen analysieren (SaaS).
Außerdem bieten Big-Data-Plattformen bereits ausgereifte Dienste, die in einer Cloud-Struktur zur Verfügung stehen und kein explizites internes Know-how erfordern.
Microsoft und IBM decken Big-Data-Anforderungen ab
 Als Anbieter von Big-Data-Lösungen finden sich aus Sicht der Anwender, wie zu erwarten, die großen Unternehmen wie IBM, SAP, Oracle und Microsoft an den führenden Positionen.
Als Anbieter von Big-Data-Lösungen finden sich aus Sicht der Anwender, wie zu erwarten, die großen Unternehmen wie IBM, SAP, Oracle und Microsoft an den führenden Positionen.
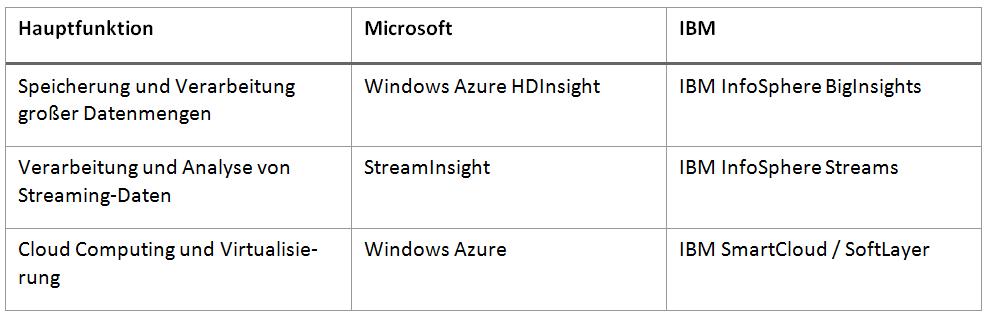
Die Tabelle (links) zeigt, welche Produkte aus den Portfolios beider Anbieter aufgrund ihrer Hauptfunktionen für Big Data-Anwendungen in der Cloud in Betracht kommen.
Microsoft hat zwar bereits länger Lösungen im Portfolio, die Big Data ergänzen, eine gezielte Behandlung von Big-Data-Anforderungen stand dabei aber bisher noch aus. Mit dem Produkt Windows Azure HDInsight spricht Microsoft nun auch direkt den Big-Data-Markt in Kombination mit Cloud Computing an. Bei HDInsight handelt es sich um eine auf Windows-Rechner zugeschnittene Distribution von Hadoop. Sie kann entweder auf eigenen Rechnerclustern oder auf Microsofts Windows Azure Cloud-Plattform betrieben werden. Mit der Erweiterung des Microsoft SQL Server namens StreamInsight wird die Möglichkeit geschaffen, kontinuierliche Datenflüsse zu analysieren und eigene Anwendungen zur Überwachung von Streaming-Daten zu entwickeln. Zusätzlich sei an dieser Stelle Project Passau (offiziell: Microsoft AzureML) genannt. Dabei handelt es sich um eine sogenannte Machine Learning Plattform, die Analysten mittels einfacher Handhabung Ad-hoc-Prognosen anhand bereits vorhandener Datenbestände ermöglichen soll. Die auf Windows Azure basierende Technologie erschien erst vor kurzem in einer Public Preview.
Bei der Big-Data-Lösung von IBM handelt es sich um keine Stand-Alone-Lösung, sondern wie auch bei Microsoft um eine Kombination aus mehreren Produkten. Dazu gehört unter anderem die Anwendung IBM InfoSphere BigInsights (kurz: IS BigInsights) für die Analyse von beliebigen Datentypen mittels Hadoop-betriebener Rechnercluster. Für die kontinuierliche Analyse von Streaming-Daten in Echtzeit bietet IBM das Produkt IBM InfoSphere Streams (kurz: IS Streams). Vor kurzem hat IBM begonnen, IaaS-Cloud-Angebote auszulagern. Diese IaaS-Aufgaben übernimmt nun das von IBM im Juni 2013 gekaufte Unternehmen SoftLayer. Somit erweitert IBM sein SmartCloud-Portfolio um mehrere Rechenzentren weltweit und kann skalierbare und dedizierte Rechenressourcen für Big Data in der Cloud bereitstellen.
Unterschiede in der Verarbeitung von Streaming-Daten
Sowohl IBM als auch Microsoft decken einen Großteil der von Anwendern genannten Anforderungen an Big-Data-Anwendungen ab. Beide können mittels Hadoop- und MapReduce-Verfahren riesige Mengen an Daten in kurzer Zeit und kostengünstig verarbeiten. Kleinere Unterschiede gibt es zum Beispiel in der Verarbeitung von Streaming-Daten. Hier kann IBM mit dem Produkt InfoSphere Streams eine besser ausgebaute und auf Unternehmen ausgerichtete Lösung anbieten. Diese lässt sich zum Beispiel mit historischen Analysen kombinieren und erleichtert somit die Durchführung notwendiger Maßnahmen in Echtzeit. Microsoft vertraut im Hinblick auf die Big-Data-Analysen auf die Integration der eigenen Business-Intelligence-Werkzeuge des MS SQL Server und der Erweiterungen von MS Excel. Dies sorgt für eine geringere Einstieghürde bei Anwendern, da sie sich in einer vertrauten Umgebung wiederfinden.
Bei IBM ist BigSheets ein wichtiger Bestandteil von InfoSphere BigInsights. Hiermit sollen große Mengen an Daten intuitiv über eine Weboberfläche analysiert und Zusammenhänge aufgedeckt werden. Der gleichzeitige Zugriff auf die Daten durch viele Anwender wird bei beiden Anbietern mit entsprechenden Zugriffskonzepten gewährleistet.
Unterschiedliche Bezugsmodelle der Anbieter
Größere Unterschiede zwischen den untersuchten Lösungen gibt es in Bezug auf die Bezugsmodelle und die Integration von Cloud Computing. Während Microsoft mit Windows Azure HDInsight die Big-Data-Funktionen mit denen einer Cloud-Plattform (PaaS) kombiniert, setzt IBM eher auf einen IaaS-Ansatz. Bis Mitte des Jahres 2013 gab es die Möglichkeit, IBMs Big-Data-Produkte wie zum Beispiel InfoSphere BigInsights innerhalb der eigenen SmartCloud-Services zu betreiben. Dabei wurden sogar vorgefertigte Images für virtuelle Maschinen angeboten. Durch die Umstellung ihres SmartCloud-Portfolios müssen potenzielle Kunden nun auf die IaaS-Dienstleistungen des Tochterunternehmens SoftLayer ausweichen. Zwar erhält der Kunde bei SoftLayer eine große Auswahl an Hard- und Software, ein sehr gut ausgebautes Netzwerk und einen etablierten IaaS-Dienstleister, allerdings wird dadurch die Konfigurations- und Einrichtungsphase der Big-Data-Lösung komplexer und zeitaufwendiger.
Gemeinsam sind beiden Anbietern die recht ähnlichen SLA-Vereinbarungen für Kunden. Bei beiden Anbietern gibt es die Möglichkeit, einen erweiterten, hierarchisch in Stufen aufgeteilten Support zu erwerben. Interessenten sollten bei der Lösungsauswahl auch auf die Lage der Rechenzentren des Dienstleisters und seiner Datenschutzmaßnahmen achten.
Microsoft und IBM bieten ausgereifte Cloud-basierte Big-Data-Anwendungen an. Bei der genaueren Untersuchung der Angebote von Microsoft und IBM fällt auch auf, dass es keine allgemeingültige Lösung für alle Herausforderungen im Zusammenhang mit Big Data geben kann. In einigen Fällen müssen sehr große Datenmengen in Form eines Stroms in Echtzeit auswertbar sein, in anderen besteht der Bedarf, historische Daten jederzeit ad hoc analysieren zu können. Dementsprechend versuchen die Big Data Anbieter, den individuellen Wünschen der Kunden nachzukommen und möglichst viele Anforderungen durch das Angebot verschiedener und spezialisierter Lösungen abzudecken.
Apache Hadoop** stellt in keinem Fall eine Gesamtlösung dar, sondern bietet vielmehr eine Basis zur Behandlung bestimmter Big-Data-Anforderungen, wie der kostengünstigen Verarbeitung großer Datenmengen in Batch-Vorgängen. Die führenden Anbieter in diesem Bereich pflegen im Wesentlichen die gleichen Vorstellungen bezüglich Big Data wie ihre Kunden. IBM und Microsoft versuchen die Einstiegshürde mittels angepassten, auf ihre Kunden zugeschnittenen und übergreifenden Unternehmenslösungen zu verringern.
Die Verknüpfung von Cloud Computing und Big Data wird unterschiedlich umgesetzt. Microsofts PaaS-Ansatz scheint auf den ersten Blick die bessere Variante zu sein. Aber auch eine Big-Data-Lösung in Kombination mit einem IaaS-Dienstleister bietet Vorteile, wie IBM zeigt. Norman Bernhardt, Viktor Adler/hei
Die Autoren*
 Norman Bernhardt berät als Senior Consultant und Projektmanager bei der pmOne AG Kunden der unterschiedlichsten Branchen zum Themengebiet Data Warehouse/Business Intelligence. Darüber hinaus beschäftigt er sich mit der Erforschung der Potentiale des Cloud Computing für das Anwendungsfeld Business Intelligence. Im Rahmen seiner Promotion an der Steinbeis Hochschule Berlin erarbeitet Norman Bernhardt ein Entscheidungsmodell für den Einsatz von Business-Intelligence-Lösungen auf der Basis von Cloud-Computing-Technologien.
Norman Bernhardt berät als Senior Consultant und Projektmanager bei der pmOne AG Kunden der unterschiedlichsten Branchen zum Themengebiet Data Warehouse/Business Intelligence. Darüber hinaus beschäftigt er sich mit der Erforschung der Potentiale des Cloud Computing für das Anwendungsfeld Business Intelligence. Im Rahmen seiner Promotion an der Steinbeis Hochschule Berlin erarbeitet Norman Bernhardt ein Entscheidungsmodell für den Einsatz von Business-Intelligence-Lösungen auf der Basis von Cloud-Computing-Technologien.
 Viktor Adler ist seit 2011 bei der pmOne AG als Consultant tätig. Sein Fokus ist das Design und die Entwicklung von Data-Warehouse-Lösungen auf Basis der Technologien von Microsoft.
Viktor Adler ist seit 2011 bei der pmOne AG als Consultant tätig. Sein Fokus ist das Design und die Entwicklung von Data-Warehouse-Lösungen auf Basis der Technologien von Microsoft.
Apache Hadoop als Basis für Big-Data-Anwendungen**
Die Grundlage vieler Big-Data-Lösungen bilden die Entwicklungen rund um Apache Hadoop. Zwar stellen sie nicht die Lösung für alle Big-Data-Anforderungen dar, aber viele Unternehmen und Entwickler erkennen das Potenzial und investieren in dieses Thema. Laut dem BARC Big Data Survey Europe haben bereits 14 Prozent der Befragten Hadoop in Betrieb. Weitere 30 Prozent planen eine zukünftige Integration.
Bei Apache Hadoop handelt es sich um ein von Googles MapReduce-Ansatz inspiriertes Framework für verteilte und skalierbare Software. Dieses Open Source Framework wurde entwickelt, um riesige Datenmengen kosteneffizient und schnell abzuspeichern und ebenso kosteneffizient und schnell zu laden bzw. zu verarbeiten. Daher ist es prädestiniert für den Einsatz in Big-Data-Anwendungen. Allgemein sind die Hadoop-Technologien dafür ausgelegt, große Mengen an unstrukturierten oder semistrukturierten Daten zu verwalten. Wichtig dabei ist, dass diese Daten, nachdem sie einmal abgespeichert wurden, selten oder gar nicht mehr geändert werden müssen. Hadoop Distributed File System (kurz: HDFS) entspricht dabei dem verteilten Dateisystem und MapReduce der Verarbeitungslösung. Zusammen stellen sie die Kernbestandteile von Apache Hadoop dar. Es gibt allerdings zahlreiche weitere Applikationen und Ergänzungen, die für den Betrieb von Apache Hadoop wichtig sind.





