Fivetran, führender Anbieter für automatisierte Datenbewegungen, hat gemeinsam mit Brooklyn Data Co. die Geschwindigkeit und Kosten von fünf der beliebtesten Cloud Data Warehouses verglichen. Unter die Lupe genommen wurden Amazon Redshift, Snowflake, Google BigQuery, Databricks und Azure Synapse. Die Ergebnisse präsentiert Fivetran jetzt in seinem neuesten Cloud Data Warehouse Benchmark.
Die Ergebnisse des Cloud Data Warehouse Benchmark von Fivetran:
- Alle fünf Data Warehouses punkten mit einer hervorragenden Ausführungsgeschwindigkeit und eignen sich für interaktive Ad-hoc-Abfragen.
- Alle fünf Data Warehouses haben ihre Leistung seit dem letzten Benchmark im Jahr 2020 verbessert.
- Die größten Verbesserungen erzielte Databricks aufgrund einer neuen SQL-Ausführungs-Engine.
- Die Kosten sind bei allen fünf betrachteten Data Warehouses ähnlich niedrig.
- Die wichtigsten Unterschiede bestehen in den Designansätzen und den daraus resultierenden Qualitätsunterschieden mit Fokus entweder auf Optimierungsmöglichkeiten oder Benutzerfreundlichkeit.
„Als Anbieter von Data Pipelines, die Daten aus Apps, Datenbanken und File Stores in die Data Warehouses unserer Kunden synchronisieren, werden wir häufig gefragt: ‚Welches Data Warehouse ist für uns das richtige?‘“, so George Fraser, CEO von Fivetran. „Deshalb haben wir jetzt zum zweiten Mal diesen Benchmark-Test durchgeführt. Mit den Ergebnissen können wir empfehlen, das Hauptaugenmerk bei der Auswahl eines Data Warehouses auf die Benutzerfreundlichkeit zu legen.“
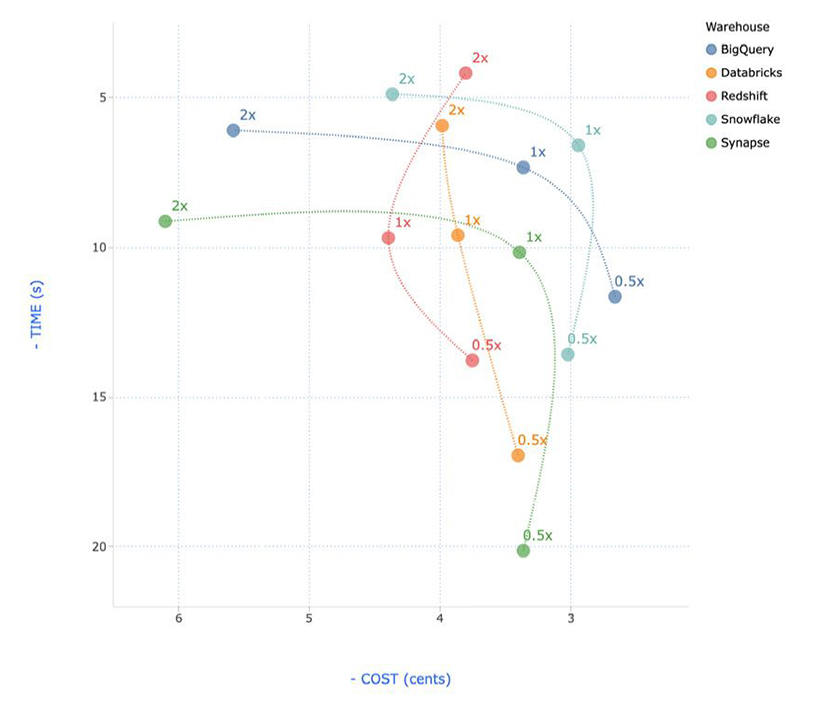
Kostenvergleich der getesteten Data Warehouses
Quelle: Fivetran
Basis für den Benchmark Report ist ein typischer Fivetran-Nutzer. Dieser synchronisiert Daten aus Salesforce, JIRA, Marketo, Adwords und aus seiner Oracle-Datenbank in sein Cloud Data Warehouse. Die Datenquellen sind nicht sehr groß, sie enthalten üblicherweise höchstens einige hundert Gigabyte. Mit hunderten normalisierten Tabellen, die mithilfe komplexer SQL-Abfragen zusammengefasst werden, sind diese jedoch relativ komplex.
Auch die Abfragen, die Fivetran gemeinsam mit Brooklyn Data durchgeführt hat, waren komplex: Sie umfassten zahlreiche Join-Operationen, Aggregationen und Unterabfragen. Für den Benchmark wurden 99 Abfragen sequenziell, also nacheinander, durchgeführt. Dabei kam jede Abfrage nur einmal zum Einsatz, um ein Zwischenspeichern auszuschließen.
Mehr Informationen zu den Ergebnissen und dem Vorgehen sowie Vergleiche zu anderen Benchmark-Tests im aktuellen Fivetran „Cloud Data Warehous Benchmark“ – hier zum Download. we





